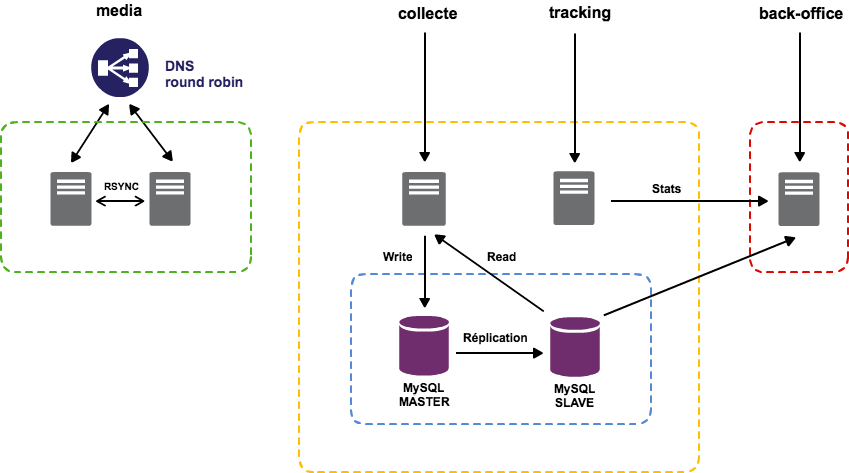
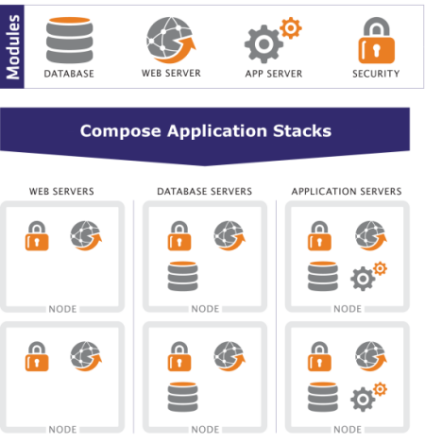
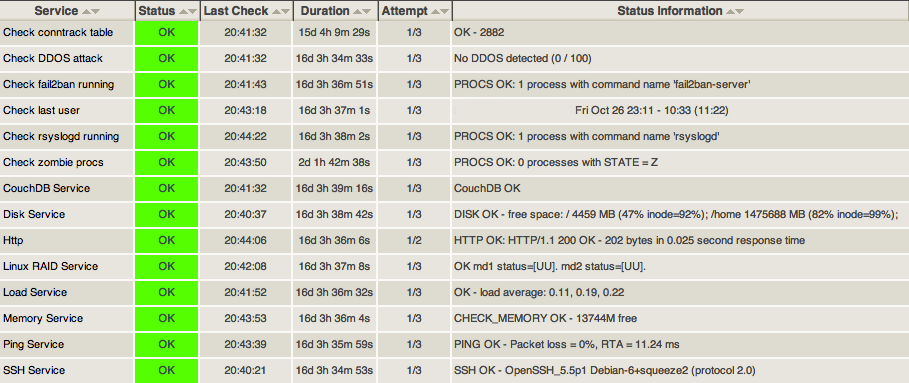
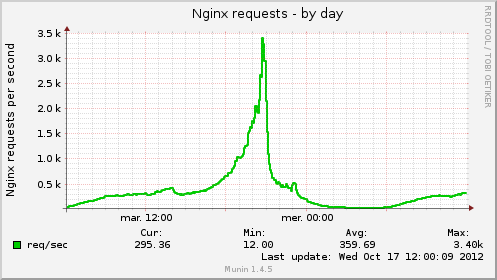
Benjamin Dos Santos
- Je travaille chez Arthur Media Group depuis deux ans
- Développeur Web la première année
-
Administrateur système depuis un an :
- Déploiement / Administration / Supervision des infrastructures
- Évolution de l'existant